Misc-隐写术
转载自风之轻语
隐写术
概述
STEGA即隐写术,将信息隐藏在多种载体中,如:视频、硬盘和图像,将需要隐藏的信息通过特殊的方式嵌入到载体中,而又不损害载体原来信息的表达。旨在保护需要隐藏的信息不被他人识别。信息隐蔽技术有:
- 隐写术
- 数字水印
- 隐蔽信道
- 阀下信道
- 匿名信道
文件格式及文件头
图片类
| 文件类型 | 后缀 | 文件头 | 文件尾 | 标志 |
|---|---|---|---|---|
| JPEG | .jpg/.jpeg | FFD8FF | FFD9 | JFIF |
| PNG | .png | 89504E47 | AE426082 | PNG IEND IHDR |
| GIF | .gif | 47494638 | 003B | GIT9a |
| TIFF | .tif/.tiff | 49492A00 | 4D4D2A00 | - II MM |
音频类
| 文件类型 | 后缀 | 文件头 | 文件尾 | 标志 |
|---|---|---|---|---|
| WAVE | .wav | 52494646 | - | RIFF |
压缩文件类
| 文件类型 | 后缀 | 文件头 | 文件尾 | 标志 |
|---|---|---|---|---|
| ZIP Archive | .zip | 504B0304 | - | PK |
| RAR Archive | .rar | 52617221 | - | RAR! |
| 7Z Archive | .7z | 377ABCAF | - | 7z |
文本文档类
| 文件类型 | 后缀 | 文件头 | 文件尾 | 标志 |
|---|---|---|---|---|
| XML | .xml | 3C3F786D6C | - | - |
| HTML | .html | 68746D6C3E | - | - |
| Adobe PDF | 255044462D312E | - | %PDF %%EOF |
图片隐写
- 一、附加式的图片隐写
- 二、基于文件结构的图片隐写
- 三、基于LSB原理的图片隐写
- 四、基于DCT域的JPG图片隐写
- 五、数字水印的隐写
- 六、图片容差的隐写
附加式图片隐写

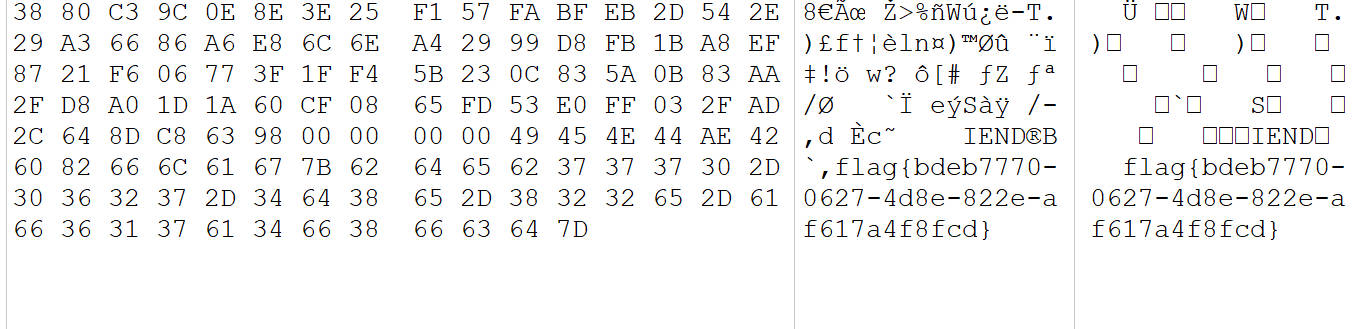
拿到图片后打开,没有发现任何异常,猜测flag在图片数据中,使用kali自带的strings工具搜索字符串

可以看到flag出来了,或者使用winhex等可以查看文件数据的都可以拿到flag
文件的数据格式,是由文件头及具体的数据内容决定的,所以我们可以将两种格式的文件数据拼接,这样就达到了使用一个文件,存放n种文件的效果
图种:
一种采用特殊方式将图片文件(如jpg格式)与rar文件结合起来的文件。该文件一般保存为jpg格式,可以正常显示图片,当有人获取该图片后,可以修改文件的后缀名,将图片改为rar压缩文件,并得到其中的数据。
图种这是一种以图片文件为载体,通常为jpg格式的图片,然后将zip等压缩包文件附加在图片文件后面。因为操作系统识别的过程中是,从文件头标志,到文件的结束标志位,当系统识别到图片的结束标志位后,默认是不再继续识别的,所以我们在通常情况下只能看到它是只是一张图片。

这样一张图片,同样的,我们也无法通过图片表面去发现,这里说一下如何判断图片中是否隐藏有其他文件
隐藏文件检测
- 通过文件大小判断:正常的图片大小不会很大,如果发现文件大小几M几十M,甚至几百M,基本可以判断其中有隐藏文件
- 通过工具判断:可以使用binwalk一键检测或者winhex手动查看文件
隐藏文件分离
使用kali自带的binwalk工具检测分离
binwalk 文件名 #按照文件头检测文件
binwalk 文件名 -e #将检测到的文件提取出来
使用winhex手动分离
使用winhex打开,按照文件头查找,将非图片数据的内容选中,右键编辑,复制选块到新文件,保存为zip文件
基于文件结构的隐写
对于一个正常的PNG图片来讲,其文件头总是由固定的字节来表示的,以16进制表示即位 89 50 4E 47 0D 0A 1A 0A,这一部分称作文件头。
标准的PNG文件结构应包括:
PNG文件标志
PNG数据块
PNG图片是有两种数据块的,一个是叫关键数据块,另一种是辅助数据块。正常的关键数据块,定义了4种标准数据块,每个PNG文件都必须包含它们。
它们分别是长度,数据块类型码,数据块数据,循环冗余检测即CRC。
我们这里重点先了解一下,png图片文件头数据块以及png图片IDAT块,这次的隐写也是以这两个地方为基础的。
png图片文件头数据块
即IHDR,这是PNG图片的第一个数据块,一张PNG图片仅有一个IHDR数据块,它包含了哪些信息呢?IHDR中,包括了图片的宽,高,图像深度,颜色类型,压缩方法等等。 如图中蓝色的部分即IHDR数据块。
如图中蓝色的部分即IHDR数据块。IDAT 数据块
它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块。这是一个可以存在多个数据块类型的数据块。它的作用就是存储着图像真正的数据。
因为它是可以存在多个的,所以即使我们写入一个多余的IDAT也不会多大影响肉眼对图片的观察
 如图中蓝色的部分即IHDR数据块。
如图中蓝色的部分即IHDR数据块。高度被修改的隐写
png图片结构详解
开头的0-7八个字节为png的文件头:89 50 4E 47 0D 0A 1A 0A (固定格式)
8-11四个字节:00 00 00 0D 表示头部数据块的长度为13(固定格式)
12-15四个字节:49 48 44 52 表示文件头数据块的标示(固定格式)
16-19四个字节:00 00 03 84表示图片的宽(不固定)
20-23四个字节:00 00 00 96表示图片的高(不固定)
24-28五个字节:08 02 00 00 00表示Bit depth(图像深度)、ColorType(颜色类型)、 Compression method(压缩方法)、 Filter method(滤波器方法)、Interlace method(隔行扫描方法)这五个字节不固定,均为可变数据
29-32四个字节:76 EC 1E 40为图片的crc校验值由从第12个字节到第28个字节的十七位字节进行crc计算得到
解题
首先校验CRC的值是否正确,也就是查看图片有没有被修改过
使用在线校验网站:CRC校验,输入第12到第28共十七位字节,参数模型选择CRC32,点击计算,得到图片CRC校验值
若校验值与图片的CRC值不相等,则说明该图片crc校验有问题。一般是由于高度或者宽度所引起的,这里需要用到脚本对其宽高进行爆破。
1 | import binascii |
隐写信息以IDAT块加入图片
我们可以用 pngcheck -v [文件名] 去查看PNG文件数据块信息,然后利用 python zlib 解压多余IDAT块的内容,此时注意剔除长度、数据块类型及末尾的CRC校验值。
1 | import zlib |
LSB隐写
LSB,最低有效位,英文是Least Significant Bit 。我们知道图像像素一般是由RGB三原色(即红绿蓝)组成的,每一种颜色占用8位,0x00~0xFF,即一共有256种颜色,一共包含了256的3次方的颜色,颜色太多,而人的肉眼能区分的只有其中一小部分,这导致了当我们修改RGB颜色分量种最低的二进制位的时候,我们的肉眼是区分不出来的。
Stegosolve介绍
CTF中,最常用来检测LSB隐写痕迹的工具是Stegsolve,这是一款可以对图片进行多种操作的工具,包括对图片进行xor,sub等操作,对图片不同通道进行查看等功能。

我们使用Stegosolve工具来进行解题,在工具中打开文件,点击箭头切换通道
发现图片分别在红0绿0蓝0通道中发现异常

接着我们查看该通道的信息
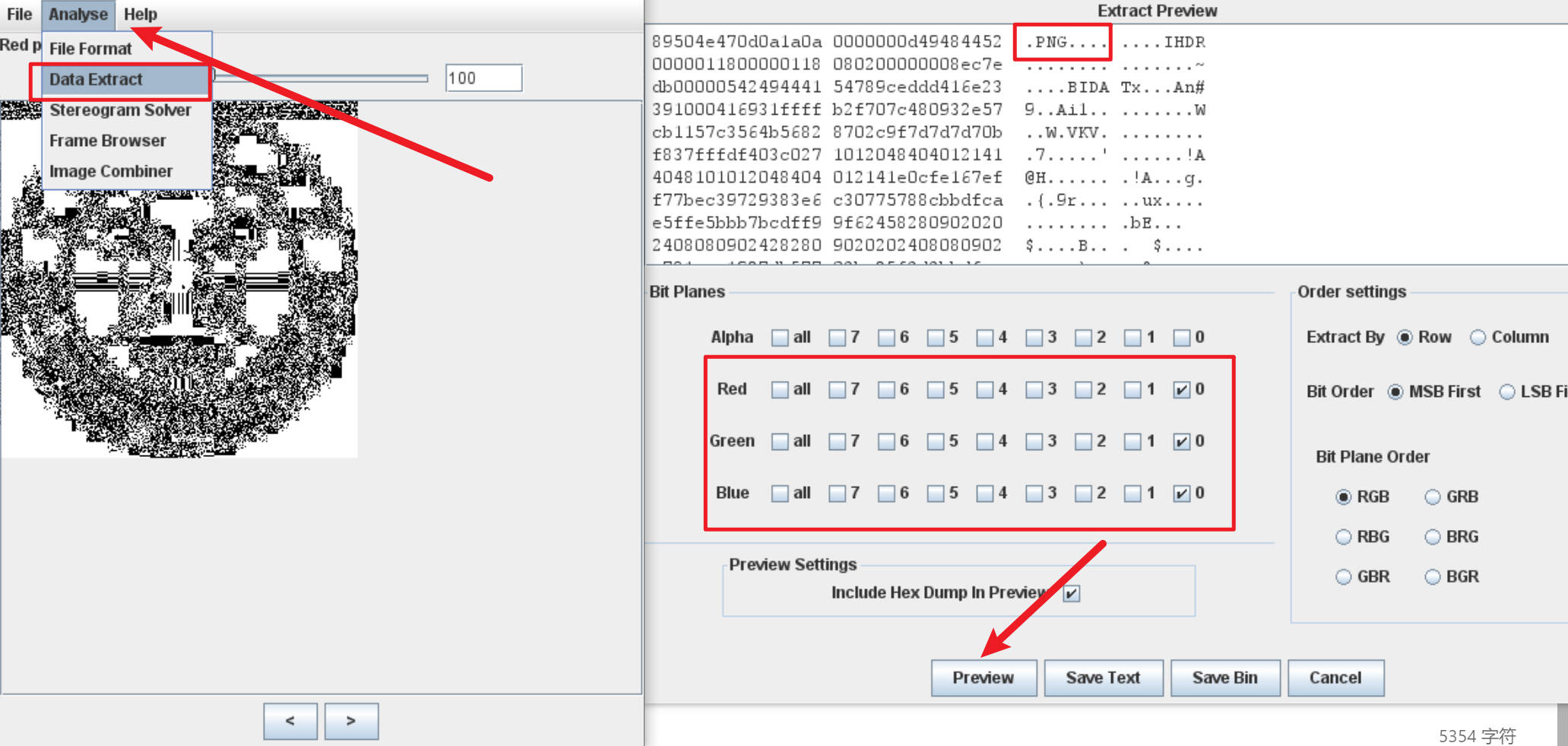
勾选上红绿蓝的异常通道后,点击预览,发现是个png格式的数据,点击保存导出为png,扫描导出的二维码图片发现flag
JPG及其他图片隐写
JPG隐写
jpg方面的隐写,有F5隐写,Outguess算法隐写,盲水印攻击等隐写
可以使用Stegdetect工具解题
Stegdetect的指令介绍
1 | -q 仅显示可能包含隐藏内容的图像。 |
GIF隐写
gif图的隐写,因为gif是动态图,所以可以像视频一样,在其中一帧中隐藏信息,或其中的帧按规律进行信息隐藏
可以使用Stegosolve查看每一帧或者导出
文档隐写
word文档
- 隐藏文字:word中可以将输入的文字隐藏,可以通过”文件”-“选项”-“显示”,将隐藏文字勾选,这样就会显示隐藏文字
- 与背景色相同:与背景色相同的文字可以选中,但是无法查看,只需要全选,然后更改文字颜色就可以了,或者Ctrl+F搜索关键字
- 嵌入图片:word中插入的图片分为嵌入式和非嵌入式,区别在嵌入式会跟着文本的位置产生移动,即有回车后,图片下移。但非嵌入的不会跟着文本走,即有回车后,图片保持原位置不动。可以将word文档后缀改为zip解压查看,或者使用binwalk、foremost等工具分离查看
- xml文件隐藏:word文档可以转为xml文件,只需要把后缀改为zip解压,解压后的文件中,可能藏有flag信息
Excel表格
excel文件和word隐藏的方式差不多,需要注意的是,在Excel中,一个工作簿可以有多个工作表,不同的表里可能会有不同的信息
NTFS数据流隐写
NTFS这里不过多介绍,只需要清楚,它的创建和打开方式是宿主:寄宿文件
比如,这里有一个txt文件,打开之后里面的内容为空,但是占用空间为22M,这很不正常

其实是我用NTFS数据流的方式放了一本小说在里面
如何查看
这么多文件,我怎么知道它是不是可疑的文件,这里就要查看一下有哪些文件是有NTFS数据流的,可以使用以下命令dir /r
如果有数据流文件的话,会在文件的后面显示**:NTFS:$DATA**,第一个冒号后面,表示的是数据流的文件名,第二个冒号后面表示是数据流
使用NtfsStreamsEditor工具可以搜索NTFS数据流文件
如何创建
- 使用命令创建:我们可以使用echo或者type等命令将数据写入到其中
1 | echo 你好 >hello.txt:world #将“你好”这句话写入hello.txt中的world数据流 |
- 使用工具创建:使用NtfsStreamsEditor工具中的“编辑”来写入
如何打开
- 使用记事本打开:正常使用记事本打开肯定是看不到的,我们需要使用命令行来打开
1 | notepad 宿主:寄宿文件 |
- 使用NtfsStreamsEditor打开
零宽字符隐写
零宽度字符是一些不可见的,不可打印的字符。它们存在于页面中主要用于调整字符的显示格式。
常见的零宽度字符及它们的unicode码和原本用途:
零宽度空格符 (zero-width space) U+200B : 用于较长单词的换行分隔
零宽度非断空格符 (zero-width no-break space) U+FEFF : 用于阻止特定位置的换行分隔
零宽度连字符 (zero-width joiner) U+200D : 用于阿拉伯文与印度语系等文字中,使不会发生连字的字符间产生连字效果
零宽度断字符 (zero-width non-joiner) U+200C : 用于阿拉伯文,德文,印度语系等文字中,阻止会发生连字的字符间的连字效果
左至右符 (left-to-right mark) U+200E : 用于在混合文字方向的多种语言文本中(例:混合左至右书写的英语与右至左书写的希伯来语),规定排版文字书写方向为左至右
右至左符 (right-to-left mark) U+200F : 用于在混合文字方向的多种语言文本中,规定排版文字书写方向为右至左
怎么实现的怎么实现的?
首先,输入需要被加密的内容将被转换为其二进制形式,然后该二进制将被转换为一系列表示每个二进制数字的零宽度字符。然后可以将零宽度的字符串不可见地插入正常文本中。如果将文本粘贴在其他地方,则可以提取零宽度的字符串,然后反向进行操作以找出被加密的内容!
具体加密过程
- 将需加密的内容转换为二进制
只是将每个字符转换为其等效的二进制
1 | const zeroPad = num => ‘00000000’.slice(String(num).length) + num; |
- 将二进制转换为0宽字符
它将遍历二进制字符串,并将每个1转换为0宽度空间,将每个0转换为零宽非连接符。转换字母后,我们将插入0宽连接符,然后再下一个。
1 | const binaryToZeroWidth = binary => ( |
- 插入正常文本中
需要注意的是加密与解密所使用的字典必须一致,也就是说,在哪儿进行加密的,就要在哪儿解密。
Base64隐写
前言
在了解base64隐写之前,我们先来了解一下base64编码。
base64编码是现在网络上最常见的用于传输8Bit字节码的编码方式之一。在最初有的网络并不支持所有的字节,比如某些系统只支持可见字符的传送,比如图片二进制流的每个字节不可能全部是可见字符,所以就传送不了。所以由于不能传送ASCII的控制字符,它的用途就受到了很大的限制。
而Base64旨在通过一种方法,把所有的字符都用64个特定的可打印字符表示来实现传送。选定的64个字符如下:
| 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 |
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | ||
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y |
加密过程
由于只用到了64个字符,所以使用6个二进制位(2^6 = 64)完全可以把所有的字符表示出来,于是原来的1个字节8位在base64编码中变成了1个字节6位。
换言之:把原本的3个字节变成现在的4个字节,因为(3*8 == 4*6)
所以在加密的时候首先写出原字符ASCII码对应的二进制数字,每个字符都可以得到一个8位的01串,再把该01串重新按照每6位一组划分即可得到一个新的数字,对照上图给出的表格可以得到一个新的字符。
但是这里有一个问题了:如果明文的字节数刚好是3的倍数那没有问题,按照6位一组划分肯定是刚刚好的;但是如果明文的字节数不是3的倍数,那按照6位一组划分不是就有剩余了吗?具体可见下图:
这样是没有剩余的:
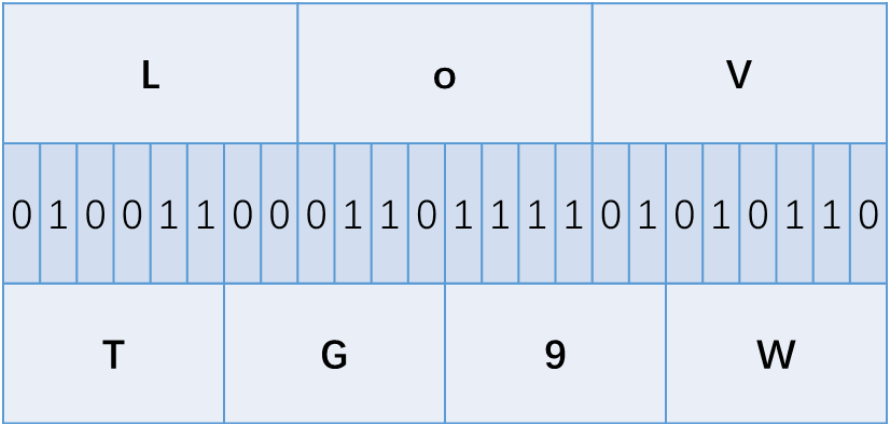
而这样是有剩余的:
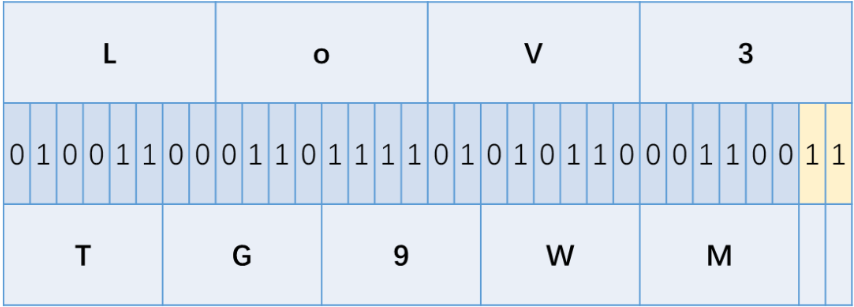
而base64给出的解决方法是在二进制数串后面加0,一直到二进制数串变成8和6的公倍数,然后把只有0的字节编码成”=”,如下图:
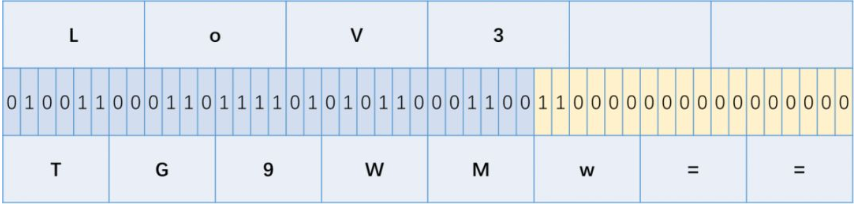
所以LoV3被编码成了TG9WMw== ,同时base64编码后面最多只可能出现2个==
解密过程
解密的过程可视作加密的逆过程
由于”=”是最后为了补齐填充的,所以解密的时候首先把”=”删去,然后写出二进制数串,然后从左往右每8位一组,剩余的不足8位丢掉,然后根据转换表获得相应字符:
以上图为例,TG9WMw==首先变成了TG9WMw,对照上图的表写出来二进制数串:
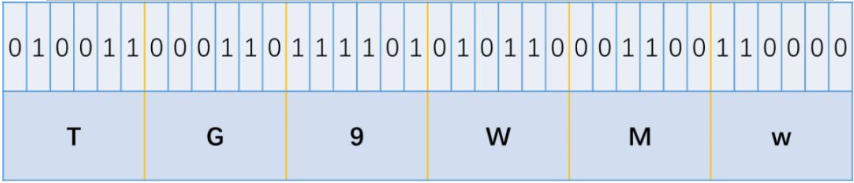
然后每8位一组,剩余不足的丢弃:
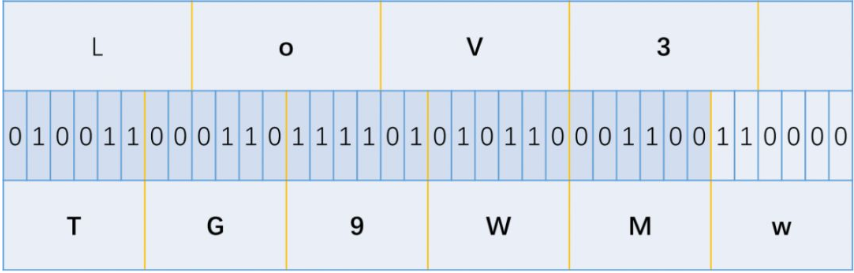
所以这里牵涉到了一个地方,由上面的过程我们可以看成,TG9WMw在解密回LoV3的时候,按每8位一组剩余的丢弃来算,最后的110000中的0000是没有用到的。所以换句话说,这剩下的4位无论是0000还是1111,都是要被丢弃的,所以这就提供了一个可以隐藏信息的地方:
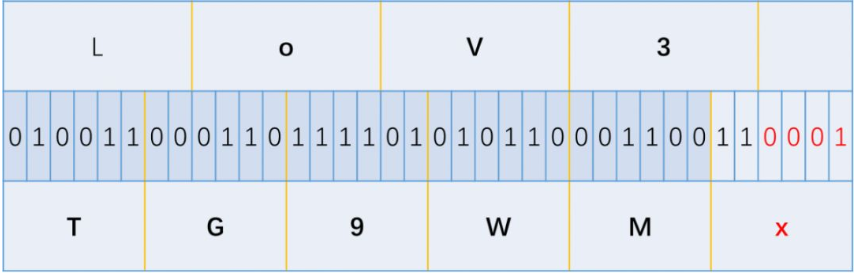
TG9WMx==解密后依然是LoV3,但已经隐藏进了一个1进去,那么这就是base64隐写
那么,在平时我们如何判断有没有信息被隐藏进去了呢
最简单的就是你是否隐藏信息,解密得到的明文是不变的,那么你重新按照正确的加密流程计算一遍,如果发现结果不一样,那么就说明隐藏进了信息。
一般CTF题目中出现一大堆base64编码字符串的时候,更需要考虑base64隐写
这里附上一个base64提取隐藏信息的脚本:
1 | b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' |
其他文件隐写
压缩包
一、zip
CTF中的压缩包隐写一般有这样几个套路
1、通过编码转换隐藏信息(common)
比如给出一堆字符或数字,仔细观察为某种进制,将其解码为十六进制,观察其文件头是压缩包或者是其他格式,修改后缀名后解压得flag
2、在文件中隐藏压缩包(图种)
在CTF压缩包隐写中最为常见,多用于在一个文件中隐藏一个压缩包
原理:以jpg格式为例,完整的JPG由FF D8开头,FF D9结束,图片浏览器会忽略FF D9之后的内容,因此可以在JPG文件之后加入其他的文件。
利用foremost,dd或者直接将其修改为压缩包后缀进行提取。
推荐使用foremost,因为foremost还可以分离其他隐藏的文件。
修改为ZIP文件虽然方法简单,但是如果隐写了多个文件时可能会失败。
以前不知道foremost的时候一直是用dd分离的,后边知道了foremost就一直用的foremost。
3、伪加密
原理:ZIP伪加密是在文件头的加密标志位进行修改,进而再次打开文件时被识别为加密压缩包。
ZIP文件主要由三个部分组成:压缩源文件数据区 + 核心目录 + 目录结束标志
压缩源文件数据区
local file header + file data + data descriptor
1 | local file header:文件头用于标识该文件的开始,记录了该压缩文件的信息, |
6B65792E7478740BCECC750E71ABCE48CDC9C95728CECC2DC849AD284DAD0500 (直到核心目录文件头标识)
压缩源文件目录区
记录了压缩文件的目录信息,在这个数据区中每一条纪录对应在压缩源文件数据区中的一条数据。
1 | 50 4B 01 02:目录中文件文件头标记(0x02014b50) |
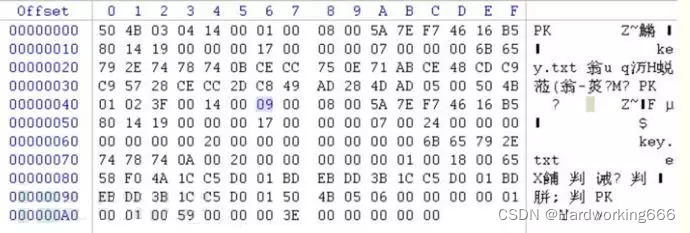
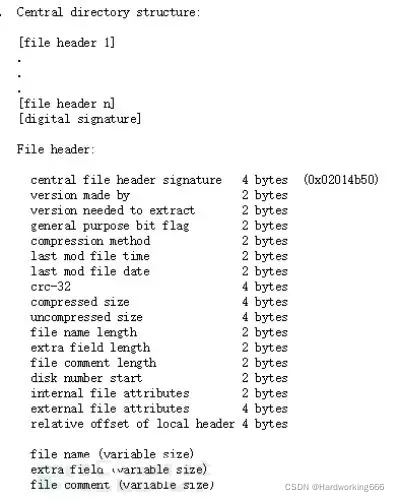
目录结束标识
存在于整个归档包的结尾,用于标记压缩的目录数据的结束。每个压缩文件必须有且只有一个结束标识。
1 | 50 4B 05 06:目录结束标记 |
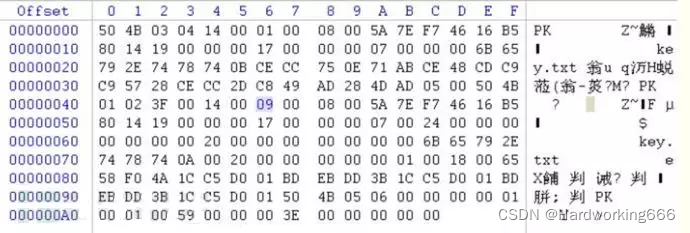
zip伪加密
zip伪加密是在文件头的加密标志位做修改,进而再打开文件时识被别为加密压缩包。
如果把第二个加密标记位的00 00改为09 00,打开就会提示有密码: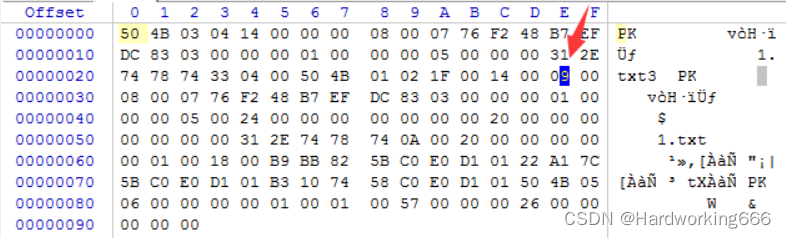
其实改成09只是举的一个例子,只要末位是奇数,就代表加密,反之,末位是偶数代表未加密。
有时这里是01,也代表加密!不用更改!
识别真假加密
无加密
压缩源文件数据区的全局加密应当为00 00
且压缩源文件目录区的全局方式位标记应当为00 00
假加密
压缩源文件数据区的全局加密应当为00 00
且压缩源文件目录区的全局方式位标记应当为09 00
真加密
压缩源文件数据区的全局加密应当为09 00
且压缩源文件目录区的全局方式位标记应当为09 00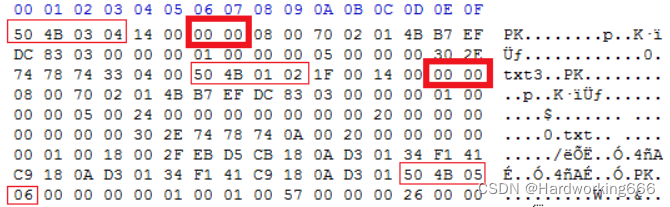
二、RAR
文件格式
RAR 文件主要由标记块,压缩文件头块,文件头块,结尾块组成。
其每一块大致分为以下几个字段: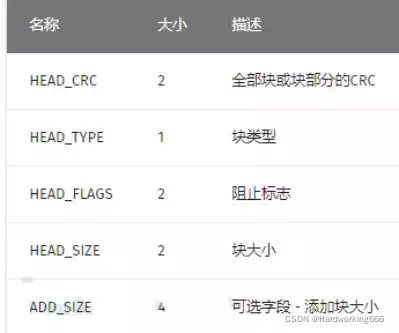
RAR压缩包的文件头为:52 61 72 21 1A 07 00
其后是标记块(MARK_HEAD),还有文件头(FILE_HEAD)。
主要攻击方式
1、爆破
利用linux下的rarcrack(http://rarcrack.sourceforge.net/)
2、伪加密
RAR 文件的伪加密在文件头中的位标记字段上,用 010 Editor 可以很清楚的看见这一位,修改这一位可以造成伪加密。
3、其他如明文攻击等方法与ZIP相同。
音频
摩斯密码
播放音频文件,可以听到有规律的长短音,使用Audacity工具打开,可以看到波形图,使用0和1或者·和-记录下来
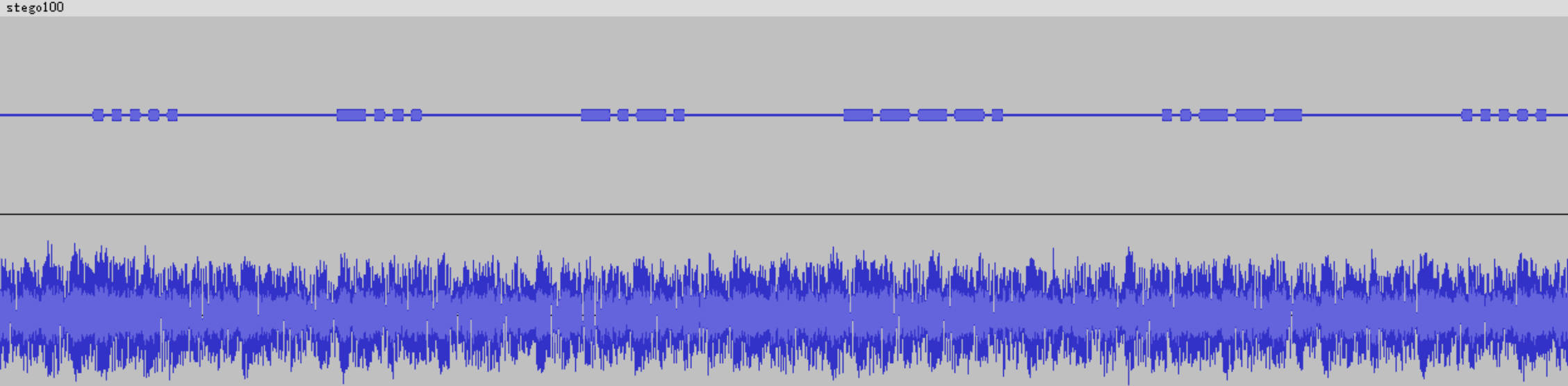
放到相关工具或在线解码网站解密
使用python脚本解密
1 | import argparse |
频谱图
将音频频谱放大或缩小,直到出现有效信息

- wechat